

استخراج کل url های یک صفحه از سایت برای موارد زیادی استفادهمی شود . ساخت نقشه سایت (sitemap) از آدرس url سایت یکی از اینموارد است . شما می توانید به راحتی همه url های یک صفحه را توسط php استخراج کنید . در این آموزش به شما کد php کوتاه و ساده برای استخراج کل url های یک صفحه توسط php ارایه دادیم.
کلاس DOMDocument در PHP کاربردهای سودمندی از جمله خواندن و نوشتن در فایل های xml و html را دارد. با کمک آن می توان فایل های xml و html را باز کرد و اطلاعات آن را پارس کرد. این کلاس به صورت پیش فرض در php موجود می باشد و نیازی به هیچ کاره اضافه برای کار با آن نمی باشد. همچنین DOMDocument خود نیز از کلاس DOMNode مشتق شده است.
کد php زیر به شما کمک می کند که کل لینک های یک صفحه وب را دریافت کنید. از تابع File_get_contents() برای دریافت محتویات یک صفحه وب از url یا یک فایل استفاده کردیم . اطلاعات دریافت شده از صفحه در متغییر $urlContent ذخیره می شود. تمام url ها یا لینک ها از صفحه وب html توسط کلاس DOMDocument استخراج می شود. همه لینک ها قبل از ذخیره شدن در متغیر توسط FILTER_VALIDATE_URL اعتبار سنجی می شوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<?php $urlContent = file_get_contents('http://netparadis.com'); $dom = new DOMDocument(); @$dom->loadHTML($urlContent); $xpath = new DOMXPath($dom); $hrefs = $xpath->evaluate("/html/body//a"); for($i = '0' ; $i < $hrefs->length; $i++){ $href = $hrefs->item($i); $url = $href->getAttribute('href'); $url = filter_var($url, FILTER_SANITIZE_URL); // validate url if(!filter_var($url, FILTER_VALIDATE_URL) === false){ echo '<a href="'.$url.'">'.$url.'</a><br />'; } } ?> |
خروجی :
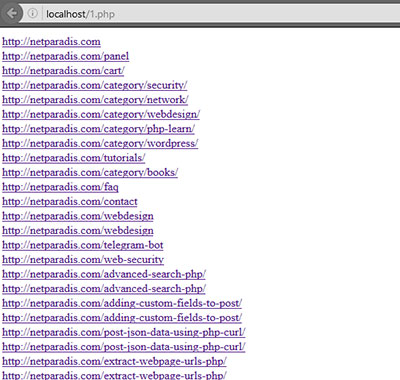
امیدوارم این کد “استخراج کل url های یک صفحه توسط php” برای شما مفید بوده باشد.







سلام مهندس . این کد رو باید داخل نوت پد کپی کنیم . یا برنامه خاصی داره
سلام. داخل نوت پد. شما باید در حد مبتدی با php آشنا باشید تا بتونید استفاده کنید
سلام و خسته نباشید
استاد چطور یک صفحه وب رو به صورت کامل استخراج کنم؟
لینک های ویدیو و…
سلام. ممنون
باید برای هر المانی که میخواید از سورس استخراج کنید یه regex بنویسید تا بین اون همه کاراکتر المان دلخواه پیدا بشه
آموزش regex
ببخشید استاد
امکان داره که سوال من رو با یک نمونه کد پاسخ بدید؟
سلام . خسته نباشید . یک سوال داشتم . برای استخراج تمام صفحه های دسته بندی که در صفحه ۱ و ۲ و ۳ ….. قرار گرفتن و از چه روشی باید استفاده کرد. من از Curl استفاده کردم برای استخراج اطلاعات . الان مشکلم اینه که فقط اطلاعات یک صفحه رو می تونم به دست بیارم . و نمیتونم پیمایش کنم و کل اطلاعات یک دسته بندی رو استخراج کنم
سلام ممنون.
باید صفحه مثلا ۲ رو باز کنید ببینید اگه url عوض میشه پس میتونید طبق اون الگو داخل curl قرارش بدید و عدد صفحه رو عوض کنید.
اگر url عوض نمیشه احتمال داره از طریق ajax این کار انجام میشه که میتونید داخل مرورگر f12 بزنید بخش network ببینید چه درخواستی به کدام آدرس ارسال میشه و به اینصورت کدتون رو بنویسید.
اگر باز url عوض نمیشه و ajax هم نیست پس مطمینا با جاواسکریپت اون رو داخل کدهای html مخفی کردند که باید داخل مرورگر view-source بزنید و پیداش کنید
سلام من میخوام از دو تا متن دو تا لینک رو استخراج کنم و لینک هارو بزارم توی دو تا پولیگون مختلف . اما لینک ها متغیر هستن ، امکانش هست راهنمایی کنید ؟؟ خیلی ممنون
سلام خسته نباشید
ممنون برای آموزش های خوبتون
من برای استخراج بعضی از سایت ها با curl مشکل پیدا می کنم . به نظر بستن سایتشونو برای ربات ها . کدام curl_setopt را باید استفاده کرد تا بتوان از این سایت ها اطلاعات استخراج کرد. اگه کدی هست که در کلیه سایت ها جواب میده برام بنویسید ممنون میشم؟
درود بر شما
درخواست کرال کردن وب سایتی رو دارم، اگه کسی میتونه انجام بده به من ایمیل بزنه
سلام خسته نباشید من میخواستم متنهای یک سایت رو با php استخراج کنم و به سک متغیر رشته ای بریزم میشه راهنمایی کنید ممنون میشم
سلام. ممنون.
یا با regex باید انجام بدید یا از dom parser استفاده کنید:
https://netparadis.com/regular-expression-regex-php
https://netparadis.com/php-simplexml-parser
https://netparadis.com/web-scraping-php
سلام
وقت بخیر
ببخشید کلاس phpcrawler با استفاده از چه روشی سورس سایت ها رو درمیاره نه curl هست نه file_get_contents
میدونید چجوری سورس سایت ها رو میخونه؟
و اگر بخوایم تغیر بدیم به curl چکار باید کرد؟
سلام. ممنون.
متاسفانه با این کتابخانه کار نکردم و از عملکرد آن اطلاعی ندارم.
باید وقت بزارید و کد را بررسی کنید.
موفق باشید.
ممنون از پاسختون
آیا میشه با
fopen()
گرفت؟
خیر. fopen برای باز کردن فایل های لوکال است.
وقتی توی کدهای پی اچ پی کرال چیزی پیدا نکردم از دو روش بالا دنبال روشهای دیگه گشتم و بلاخره با کنار هم گذاشتن چندین روش متفاوت پیدا کردم یکیش هم امروز همین fopen هست ببینید استفاده از این کد من انجام دادم
کد من
loadHTML($cod);
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate(“/html/body//a”);
for($i = ‘0’ ; $i length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
echo ‘‘.$url.’
‘;
}
}
function mytest($URL)
{
$handle = @fopen ($URL, “r”);
if ($handle === false) return false;
$buf = “”;
while (!feof ($handle)) {
$buf .= fgets($handle, 4096);
}
fclose ($handle);
return $buf;
}
?>
سلام.ممنون بخاطر آموزشهاتون یه سوال داشتم از خدمتتون من چرا هرکاری میکنم نمیتونم همه لینک های یه سایت رو در یک فایل نوت پد ذخیره کنم
و فقط یک لینک ذخیره میشه؟؟؟
میشه لطفا شما مشکلمو حل کنید
کد
loadHTML($urlContent);
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate(“/html/body//a”);
for($i = ‘0’ ; $i length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
echo ‘‘.$url.’
‘;
file_put_contents(“link.txt”, “$url”);
}
}
?>
سلام. خوشحالیم که مفید واقع شده.
باید یک فلگ داخل تابع file_put_contents اضافه کنید تا محتوای آن اور رایت نشود به اینصورت تابع مورد نظر را که در آخر کد شما هست رو تغییر بدید
file_put_contents(“link.txt”, “$url \n”, FILE_APPEND);
موفق و پیروز باشید.
عالی بود ممنون واقعا
فرض کنید من میخوام از اطلاعات یک صفحه از پیجم بکاپ بگیرم و با این روش لینکهامو ذخیره میکنم وقتی میخوام از بکاپ یا همین فایل txt استفاده کنم چجوری باید لینک ها رو یدونه یدونه وارد اسکریپت کنم وقتی از تابع file_put_contents برای باز کردن فایل درون اسکریپتم استفاده میکنم کل فایل رو باهم نشون میده و وقتی میام از ایمپلود یا اکسپولد استفاده کنم خطا میده میشه در این مورد هم کمکم کنید ممنون
کد اول برای ذخیره بکاپ لینک ها
loadHTML($urlContent);
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate(“/html/body//a”);
for($i = ‘0’ ; $i length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
echo ‘‘.$url.’
‘;
file_put_contents(“link.txt”, “$url \n”, FILE_APPEND);
}
}
?>
کد دوم برای خواندن بکاپ لینک ها
$v) {
echo ‘‘.$v.’
‘;
}
?>
خوشحالیم که مفید واقع شده.
برای خواندن فایل txt مورد نظر باید از تابع file_get_contents بصورت زیر استفاده کنید و بعد خروجی آن را میتونید explode کنید
$links = file_get_contents(“link.txt”);
تابع Explode و Implode در PHP
موفق باشید.
دقیقا همین راه رو من خودم قبلا رفتم حتی یک تابع هم نوشتم براش کنار اکسپلود ولی درست درنمیاد لطفا نگاه کنید
کد:
سلام.
کد شما اصلاح شد و نتیجه رو بصورت زیر میتونید ببینید :
موفق باشید.
سلام وقت بخیر
اگه کد شما خط ۱۲ رو اغیر بدیم و اول خط دوتا //
بذاریم
یعنی
echo ”.$url.”;
بشه
//echo ”.$url.”;
کد میشه کد زیر درسته
پس کد زیر رو لطفا تست کنید ببینید لینک هارو از فایل ذخیره شده باز میکنه یا نه
فکر کنم کدرو برای من ناقص نشون میده و قالب سایتتون کد رو تغییر داده نشون میده
کد:
evaluate(“/html/body//a”);
for($i = ‘0’ ; $hrefs->length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
//echo ”.$url.”;
file_put_contents(“mylinks.txt”, “$url \r\n”, FILE_APPEND);
}
}
$links = file_get_contents(“mylinks.txt”);
$exploded = explode(‘\r\n’, $links);
//print_r($exploded);
foreach ($exploded as $url => $value) {
return $url;
}
سلام. روی لینک سبز رنگ نمایش بیشتر بزنید تا کامل نمایش داده بشه.
موفق باشید.
سلام
ممنون از آموزشها و رسیدگیتون در قسمت نظرات
من کدی که ارسال کردم توی جواب رو روی همون کد سبز رنگ یعنی دیدن نمایش بیشتر کلیک کردم و کپی کردم عکسش رو هم توی همین پست میفرستم خودتون ببینیدش
شما همون کد که ارسال کردید خطی که توی عکس دورش خط کشیدم رو از کد بردارید و اجرا کنید و ببنید یا کد اشتباه اومده یا اشتباه نشون داده میشه
ادرس عکس
http://uupload.ir/files/hgqo_a.png
کدی که با کلیک روی نمایش بیشتر نشون میده:
loadHTML($urlContent);
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate(“/html/body//a”);
for($i = ‘0’ ; $hrefs->length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
echo ”.$url.’
‘;
file_put_contents(“mylinks.txt”, “$url \r\n”, FILE_APPEND);
}
}
$links = file_get_contents(“mylinks.txt”);
$exploded = explode(‘\r\n’, $links);
//print_r($exploded);
foreach ($exploded as $url => $value) {
return $url;
}
سلام وقت بخیر
من یه راه دیگه بنظرم رسید فایل رو از طریق
تابع file بازکردنی بدون مشکل نشون میده
ممنونم از توضیح هاتون
یه سوال دیگه داشتم من برای اینکه فقط لینک هایی که
پسوند صفحه اونها xml هست رو برام جمع کنه و لینک های عادی رو جمع نکنه عبارت با قاعده اون رو میشه لطف کنید بهم بگید من برنامه هم دانلود کردم برای اینکه این عبارات رو درست بنویسم ولی همه کدهام یه اشکالی دارن برای بهتر نوشتن این عبارات از چه برنامه ای میشه استفاده کرد تو یه فیلم اموزشی دیدم طرف کد اچ تی ام ال رو انتخاب میکرد و برنامه عبارت باقاعده رو میداد شبیه این رو سایت ریجیکس داره ولی بازم برای افراد حرفه ای خوبه
ممنون از کمکاتون
در مورد اسکریپت بالا برای اینکه فقط لینک هایی که
پسوند صفحه اونها xml هست رو برام جمع کنه و لینک های عادی رو جمع نکنه عبارت با قاعده اون رو میشه لطف کنید بهم بگید من برنامه هم دانلود کردم برای اینکه این عبارات رو درست بنویسم ولی همه کدهام یه اشکالی دارن برای بهتر نوشتن این عبارات از چه برنامه ای میشه استفاده کرد تو یه فیلم اموزشی دیدم طرف کد اچ تی ام ال رو انتخاب میکرد و برنامه عبارت باقاعده رو میداد شبیه این رو سایت ریجیکس داره ولی بازم برای افراد حرفه ای خوبه
ممنون از کمکاتون
سلام.
در مورد برنامه مورد نظر شما اطلاعی ندارم ولی عبارت با قاعده ای که میخواهید به صورت زیر می توانید استفاده کنید :
لینک تست : https://regex101.com/r/lpKfoL/1
موفق باشید.
سلام وقت بخیر ممنون دستتون درد نکنه
من اینو استفاده کردم ولی داخل برنامه لینک های شبیه الینک های زیر هست بخاطر اون باید سورس هر لینک رو ببینم صفحه برای xml هست یا html میشه بگید از چه راهی باید اقدام کنم
نمونه لینک های اسکریپت:
http://test.ir/shanbe.ba ?data
http://test.ir//mon=ox
http://test.ir/www/1/4za.xml?sge
http://teat.ir/www/zzz=sl
برنامه من یه صفحه خودکار میسازه که توش همه لینک ها هست
فایل های بک آپ برنامه پسوند xml دارن
من میخواستم از طریق این اسکریپت که معرفی کردید فقط لینک هایی که صفحه آنها xml هستن رو پیدا کنم یا اسکریپت رو کاری کنم که یک لینک به اون بدم اگر اون لینک ماله صفحه xml باشه اونو ذخیره کنه اگه نباشه ذخیره نکنه
هیچ راهی به ذهنم نمیرسه که برم دنبالش پیدا کنم
منظورم اینه ببنید
داخل صفحه
http://test.ir/shanbe.ba ?data
اگر تگی مربوط بهه فایل های xml باشه لینک رو تایید کنه یا ذخیره کنه
مثلا تگ
ممنون میشم راهنمایی کنید
باز هم بابات وسایت و آموزشهاتون تشکرمیکنم
سلام دوباره
ممنون بابت آموزشها و کمکهاتون
من مییخواستم یه همچین کدی بنویسم کد زیر فرض کنید که لینک رو بدم وارد و اطلاعات پیج توی $page_source ذخیره بشه و از طریق $chek1 و $chek2 که عبارات منظم هستن(البته متاسفانه عباراتی که من تونستم بنویسم کلا غلط هستن) بگه دو تگ زیر در کد های ذخیره شده $page_source هستند یا نه؟
وجود داره؟
کد من
<?php
$url = ('http://mywebtest.org.com/rss/2bf');
$urlContent = file_get_contents($url);
$chek1="\”;
$chek2=”\|'”;
if (strstr($urlContent,’ ‘.$chek1.’ ‘) or strstr($urlContent,’ ‘.$chek2.’ ‘)){
echo “ok”;
echo “xml link”;
}else{
echo “no”;
echo “xml link”;
}
سلام
ببخشید میشه بگید این کد رو چکار کنم درست بشه؟
کار نمیکنه
برای مثال لینک rss خودتون رو وارد کنید نمیشناسه
میشه لطفا کمکم کنید
سلام وقت بخیر
کد رو من نوشتم و خیلی هم خوب کار میکنه کد:
بجای عبارات منظم خود تگ رو گذاشتنی خوب کار میکنه
<?php
$url = ('http://mywebtest.org.com/rss/2bf');
urlContent = file_get_contents($url);
$chek1=('’);
$chek2=”;
if (strstr($urlContent,$chek1)or strstr($urlContent,$chek2)){
//echo “ok”;echo “xml link”;
echo ‘‘.$ab2url.’
‘;
// echo $ab1url;
}else{
echo “no”;echo “xml link”;
}
سلام
وقت بخیر
من میخواستم ببینم با همینکار چکار کنم لینک های ذخیره شده که قبلا توی فایل بکاپ ما ذخیره شده دیگه ذخیره نشن مثال زیر رو ببینید من تست کردم ولی فرقی نداره باشه یا نه
کد من=
loadHTML($urlContent);
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate(“/html/body//a”);
for($i = ‘0’ ; $i length; $i++){
$href = $hrefs->item($i);
$url = $href->getAttribute(‘href’);
$url = filter_var($url, FILTER_SANITIZE_URL);
// validate url
if(!filter_var($url, FILTER_VALIDATE_URL) === false){
$chektek = file(“mylinks.txt”);
foreach($chektek as $che){
if($che == $url){
file_put_contents(“mylinks.txt”, “$url \r\n”, FILE_APPEND);
echo ‘‘.$url.’
‘;
}}}}
سلام. ممنون
باید در خود فایل جستجو کنید و اگر وجود نداشت تابع file_put_contents را اجرا کنید
سلام ممنون انجام دادم متشکرم
با سلام خدمت شما و پیشاپیش تبریک عید خدمتتون
خواستم بابت وبتون تشکر کنم و یه سوال برام پیش اومد
درجواب این دوست ما که گفتید باید در خود فایل سرچ کنن منظورتونو میشه دقیقتر بگید
یا روی کدی که داده اند نشان بدهید
آیا منظورتون همون راهی هست که ایشون رفته ان یا استفاده از تابع های جستوجو در متن هست مانند strpos
یه سوال هم داشتم تو یه سوال که گفته بودن میخوان کل لینک های یه سایت رو سرچ کنن گفتید “این مورد crawl کردن است که حتما همراه با جستجو خود این کلمه رو هم اضافه کنید که لینک های یک صفحه رو میگیره و بصورت parent و child تا جایی که ممکنه پیش میره و لینک در لینک کل ایمیل ها رو بیرون میکشه .”
میشه یه جمله که برای سرچ کردن توی گوگل باید زد رو مثال بزنید این هایی که گفتیدرو من میزنم و چیز ی نمیاد خودم یه اسکریپت نوشتم که کل لینک های یه سایت یا کل لینک های خودسایت و لینک های خارجی سایت رو پیدا میکنه ولی خیلی اصولی نیست
چه جمله ای تو گوگل سرچ کنم یا اگه لینکی دارید میشه بدید
ممنون بخاطر پاسختون
سلام. خوشحالیم که مفید واقع شده.
web scraping رو جستجو کنید :
https://netparadis.com/web-scraping-php
موفق باشید.
ممنون آقای شفیعی برای رسیدگی سریعتون
برای ”
باید در خود فایل جستجو کنید و اگر وجود نداشت تابع file_put_contents را اجرا کنید ”
از تابع های سرچ در متن استفاده کنم یا یه دستور شرطی شبیه اونی که بالا داده ان میشه یا استفاده یه دستور شبیه به چیزی که برای جلوگیری از ثبت دادع تکراری توی دیتابیس هست؟
بهتره اراده به خرج بدید جستجو کنید و جواب رو پیدا کنید
https://sabzdanesh.com/%D8%AC%D8%B3%D8%AA%D8%AC%D9%88-%D8%AF%D8%B1-%D8%B1%D8%B4%D8%AA%D9%87-%D9%85%D8%AA%D9%86%DB%8C-%D8%A8%D8%A7-php
سلام
در زمینه URL rewrite به کمک PHP برای سایت های داینامیک آموزشی دارید؟ باتشکر
سلام. بفرمایید
https://netparadis.com/generate-seo-friendly-url-in-php
خیلی ممنون آقای شفیعی
سایتتون رو که نگاه کردم متوجه شدم چقدر جامع و قدم به قدم مسائل رو توضیح دادید.
از اینکه یه هموطن مفید مثل شما دارم افتخار میکنم …
خواهش می کنم. خیلی لطف دارید شما . همیشه موفق و پیروز باشید
از پاسخ سریعتون تشکر میکنم🌹
اگر بخام دقیق تر توضیح بدم، قصد دارم توی سورس یک صفحه وب قسمت عنوان و قیمت رو استخراج کنم!
ابتدا و انتهای عنوان و قیمت مشخصه! میخواستم بدونم کدی هست که مثلا این سناریو رو انجام بده: توی سورس صفحه قسمتی از کد که ابتداش x و انتهاش y هست رو توی یه متغییر بریزه.
خواهش می کنم. بله با regex به راحتی این کار قابل انجامه که باید الگوی مورد نظر رو بنویسید.
https://netparadis.com/regular-expression-regex-php/
همچنینآموزش web scrapping رو هم میتونید مطالعه کنید
موفق باشید.
سلام، ممنون ازمطالب خوب و کاربردیتون.
ببخشید من تازه کارم و خیلی از توابع رو بلد نیستم! میخواستم یه کد بنویسم که آدرسای محصولات سایت که یه الگوی خاص دارن (https://site.com/product/1234/p_name) رو در بیارم و توی سورس هر محصول هم با توجه به پترنی که داره (“Product”,”name”:”تایتل محصول”,”p_name”) و (“price”:قیمت,”pricee”) اسم و قیمت محصول رو دربیارم تا اگر محصول قیمتش تغییر کرده بود متوجه بشم!
ممنون میشم اگر راهنماییم کنید 🌹🌹🌹
سلام . خوشحالم که مفید واقع شده.
دقیق متوجه کاری که میخواین انجام بدین نشدم به هر حال از لینک های زیر میتونید استفاده کنید
https://netparadis.com/php-server-variable
https://netparadis.com/regular-expression-regex-php/
موفق باشید.
با سلام خدمت شما
من یک سوال داشتم که شاید اصلا مربوط به این بحث نشه ولی خیلی مهم!
من میخواستم مثل جاوا اسکریپت وقتی یک کد php مینویسم کاربر بعد از کلیک روی یک دکمه اون کد php ارسال بشه!
مثلا ارسال ایمیل با php ، وقتی که کاربر روی یه دکمه کلیک کرد کد PHP اجرا بشه و ایمیل ارسال بشه
ممنون میشم کمکم کنید
با تشکر
سلام . برای اینکار باید از ajax استفاده کنید
آموزش ajax
موفق باشیذ.
با احترام
ممنون که پاسخ دادید!
یه سوال دیگه هم داشتم؟
چجوری میشه داده های یک فرم مثلا وبسایتمو ، داده هاشو به صفحه لاگین اینستاگرام بفرستم؟
ممنون بابت پاسخگویی سریعتون
سلام . خود صفحه api اینستاگرام رو مطالعه کنید .
https://www.instagram.com/developer
موفق باشید.
با سلام
من یه کد میخواستم که بره به آدرس مورد نظر و لینک موجود در لاین ۱۸ برداره!
برای این متدی هست ممنون میشم به ایمیلم بفرستید
سلام . از explode هم میتونید استفاده کنید ولی راحتر از اون میتونید از تابع file بهره ببرید که خط ها رو بصورت هر خانه از آرایه برگشت میده و میتونید اون رو بخونید
$lines = file('https://site.com/index.html');
echo $lines[2]; // دریافت خط ۳م
موفق باشید.
با سلام خسته نباشید ببخشید من اگ بخوام متن لینک هم بگیرم چیکار باید بکنم متاسفانه راهی ب ذهنم نرسید برای این کار تشکر بابت وبسایت خوبتون
سلام ممنون .
مقدار
nodeValueاز آبجکت$hrefشامل متن داخل تگ هستش. ($href->nodeValue)موفق باشید.
میشه بیشتر توضیح بدید یا تو کد بالا ازش استفاده کنید ممنون میشم
به جای خط ۱۵ این کد رو قرار بدید
اگر متن ها فارسی هستند به اول اسکریپت این خط رو هم اضافه کنید تا کاراکترهای فارسی درست نمایش داده بشه.
موفق باشید.
برای بدست آوردن تایتل لینک باید چکار کرد؟
echo ‘‘.$href->nodeValue.’‘;
سلام.
بفرمایید $href->getAttribute(‘title’)
موفق باشید.
واقعا ممنون بابت وب و پاسخهاتون
یه سوال هم داشتم فقط مربوط به این مطلب نیست و تو وبتون هم پیدا نکردم
برای اینکه یه کد رو که اینکد کردیم بصورت استرینگ استفاده کنیم بجز
eval
که راحت میشه شکست از چه تابع های کال بک بهتره استفاده کرد؟
لینک مقاله ای چیزی زبان اصلی هم باشه بدید ممنون میشم
سلام. خوشحالیم که مفید واقع شده.
از توابع gzinflate – str_rot13 – base64encode – mcrypt_encrypt – openssl میتونید بر کدگذاری استفاده کنید.
eval فقط کد رو اجرا میکنه و ارتباطی با رمزنگاری کدها نداره
سلام منظورم همون اجرا کننده کدها بود
بحز استفاده از
eval
, include
که کاربر برداره print جایگزین کنه کدهای اصلی چاپ میشه چه راهی هست
function_creation منقضی شده بخاطر اون جایگزین دیگه ای میخواستم
چیزی بذهنتون میرسه
مثل همیشه ممنون بابت پاسخ هاتون
سلام. متاسفانه مورد دیگری تست نکردم
با سلام خدمت شما. من این کد شمارو برای پیدا کردن url برای سایت “تابناک” میزنم نمیتونه پیدا کنه. مشکل از کجاست؟
پیشاپیش ممنون از پاسخ شما
سلام . در صفحه موردنظر حتما باید ایمیلی وجود داشته باشه تا بشه استخراح کرد . معمولا این سایت ها ایمیل کاربران رو در سورس صفحه نمایش نمیدن و عملا نمیشه کاری کرد چرا که اسکریپت ما فقط سورس صفحه رو بررسی و اگر ایمیل بود نمایش میده .
موفق باشید.
با سپاس از پاسخ شما.من منظورم لینک های سایت بود و برای ایمیل نمیخوام
احتمالا دسترسی ها رو برای ربات ها بستن و باید با ارسال کوکی و موارد دیگه سعی در استخراج لینک ها کنید که با curl به راحتی میتونید این هدرها رور ست کنید و کدهای آماده این مورد رو پیدا کنید.
ممنونم دوست عزیز
فرمودین از curl استفاده کنم. من از این کد curl در وب سایت خودتون استفاده کردم و برای چند تا سایت استفاده کردم جواب داد اما باز برای تابناک جواب نداد.
————————————————————————–
$url = “http://tabnak.ir/”;
$content = curlRequest($url);
print $content;
function curlRequest($url) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
$response = curl_exec($ch);
$body = substr( $response, $header_size );
fclose($ch);
return $content;
}
——————————————————————————————
و برای این سایت این ارور رو میده که از ارور عکس گرفتم و در آدرس زیر قابل مشاهده است.
http://uupload.ir/files/3rez_شس.jpg
خواهش می کنم .
خب مشکل از سایت مرجع نیست و کد ها ایراد داره که خطا رو هم مشاهده می کنیم.
از کد CURL زیر استفاده کنید.
مقدار متغییر
$responseشامل محتوای صفحه سایتی که تعریف کردیم است که میتوانید از تلفیق کد بالا و کد این مقاله که یک regex ساده و حلقه است, کل URL ها رو بخوانید .ولی خب سایتی که معرفی کردید بنابر چیزی که کامنت های اول خدمتتون گفتم کمی متفاوت است و جلوی یک سری از دسترسی های ربات ها رو گرفته بنابراین کد رو بصورت دیگری براتون نوشتم(همان CURL با چندین هدر مختلف دیگه) که میتونید ازش برای بدست آوردن لینک ها بهره ببرید.
کد کامل :
موفق باشید.
ممنون از شما.
ارایه ها رو هم خالی می کنه؟؟
بله همه موارد توسط خود php انجام میشه و نیاز به کار خاصی از سمت شما نیست.
سلام خسته نباشید با چه دستوری یا چه طری با php می شه بعد از اینکه کارمون با متغییر های تموم شد اون ها رو خالی کنیم که حافظه اشتغال نمونه؟
سلام .ممنون. نیاز به کار خاصی نیست بعد اجرای برنامه , هسته php خودش مقدار ها رو از حافظه موقت حذف می کنه.
موفق باشید.
ممنون از پاسختون،من الان xampp رو رو سیستم دارم سایتم یه بانک اطلاعاتی داره،کنار همون پوشه هاش هستتو پوشه کانینگ هم اسم لوکال هاستو دادم برای بانک اطلاعاتی،اما چرا وقتی حتی بانک اطلاعاتیم رو بر می دارم که کنار فایل های دیگه هست هیچ تغییر حاصل نمیشه و متو جه نمیشه بانک اطلاعاتی نیست و زمان فراخوانی داده های بانک اطلاعاتی دادها رو بایانکه بانک اطلاعاتی سرجاش نیست میاره،می خواستم بدونم تو برنامه xammppایا بانک اطلاعاتی دیگه در جای خاصی وجود داره که خودش ساخته بشه؟!!اگه هست کجاست من بانک اطلاعاتم رو با پیاچ پی ادمین دایرکت درست کردم بعد ایکسپورت کردم گذاشتم تو پوشه هایکنار فایل ها دیگه ممنون می شم راخنمایی کنید
خواهش می کنم. مطمینا فایل کانفیگ اتصال به دیتابیس در جای دیگه از این پروژه وب شماست . که خب نیاز است در حد مقدماتی php بلد باشید تا بتونید این موارد رو پیدا و تغییر بدید.
با سلام
کدتون رو اجرا میکنم این ارور میاد
Warning: file_get_contents(https://-.ir): failed to open stream: No connection could be made because the target machine actively refused it. in E:\wamp\Crawler\New folder (4)\tex.php on line 5
array(0) { } 0 email addresses in total: ;
سلام . آدرس سایت مورد نظر رو با http:// وارد کنید و سایت مورد نظر SSL نداره .
موفق باشید.
سلام ممنون از آموزش.
اگر بخواهیم برای url هایی که پیدا میکنیم یک فیلتر قرار دهیم باید چکار کنیم؟یعنی مثلا از تمام این url هایی که پیدا کردم فقط آدرسی هایی که آخرشان به .ir یا edu.com مثلا ختم میشود پیداکن.
سپاس
سلام .
باید regex نویسی رو بلد باشید و بتوانید تغییرات مورد نظر را لحاظ کنید
آموزش regular expression
موفق باشید.
سلام و عرض ادب و احترام
ممنون از مطالب مفیدتون. جناب دو سوالی برای من در رابطه با این اسکریپت ایجاد شد.
توی خط پنجم @ به چه معنایی هست. هر چی گشتم در موردش چیزی پیدا نکردم.
دومین سوال این است که چرا توی حلقه for شما به صورت استرینگ ‘۰’ را نوشتید من با اینتجر هم امتحان کردم مشکلی نداشت.
سلام . خوشحالم که مفید واقع شده .
از @ برای جلوگیری از نمایش خطا استفاده کردیم تا خطاهای مربوط به Notice و غیره حین اجرای اسکریپت نمایش داده نشه. (انواع خطاها در php)
به دلیل اینکه در سایت و قسمت کد ها ۰ رو نمایش نمیداد مجبور شدیم این مورد رو بین دوتا qoute قرار بدیم تا هنگام کپی کد ها به مشکل برنخورید .
موفق باشید.
ممنونم از شما.
ممکنه لطف کنید به راهنمایی بدین. اگه بخوام تمام صفحات یک سایت رو بگردم یا اینکه چند صفحه رو بگردم آیا کدی براش دارید ؟
ممنون
خیر دوست عزیز کد آماده ای برای این مورد نداریم . اگر php بلد باشید میتونید پیاده سازی کتید.
موفق باشید.
خیلی ممنون زحمت کشیدی.
این امکان وجود داره که خودش اتوماتیک آدرس صفحات دیگه رو پیدا کنه و بره آدرس ایمل های اونام پیدا کنه؟ یعنی یه صفحه بهش بدیم بعد بره تو به آدرس دیگه تو اون صفحه و ….. . من دنبال اینجور چیزیم. سایتای زیادی گشتم اما پیدا نکردم
خواهش میکنم . این مورد crawl کردن است که حتما همراه با جستجو خود این کلمه رو هم اضافه کنید که لینک های یک صفحه رو میگیره و بصورت parent و child تا جایی که ممکنه پیش میره و لینک در لینک کل ایمیل ها رو بیرون میکشه .
موفق باشید.
سلام . خیلی ممنون از سایت خوبتون
من یه کد مثل همین میخوام اما آدرس ایمیل هایی که توی اون سایت هست رو بهم بده و از سایتی که بهش دادم به یک آدرس دیگه بره و ایمیل های اونم در بیاره و همین جوری ادامه بده. در واقع متوقف نشه
میتونید راهنماییم کنید ؟
سپاس از شما
سلام . بله برای استخراج ایمیل صفحات وب کافیه بصورت زیر عمل کنید.
به جای
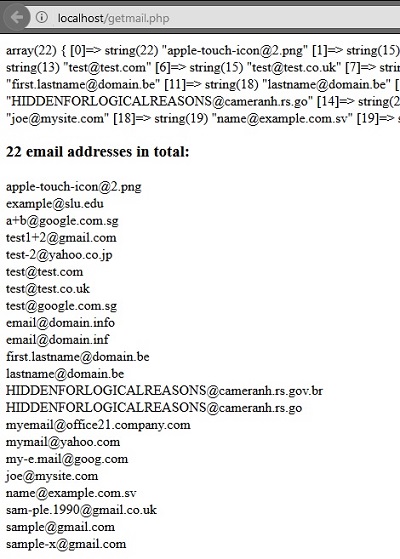
https://site.comدر خطوط اول آدرس صفحه وب مورد نظر را که واردکنید ایمیلی اگر وجود داشته باشه براتون برگشت میده .همچنین میتونید آرایه از آدرس های URL خودتون رو بسازید و در یک حلقه
foreachبزارید تا اجرا بشه و بعد استخراح ایمیل ها , در جایی مثلا فایل و یا دیتابیس ذخیره کنه.موفق باشید.
سلام
تست کردم کار نکرد!
سلام . بله به خاطر یک ; اسکریپت به درستی خروجی رو نشون نمی داد که کد رو ویرایش کردم و میتونید دوباره تست کنید و جواب می ده .

هر گونه خطای دیگری دریافت کردید ریپلای بدید تا ایشالا مشکلتون حل بشه . موفق باشید