

تقریبا هر توسعه دهنده PHP تا حالا یک سری داده ها را از وب اسکرپ کرده است. Web Scraping، روشی برای استخراج و پاکسازی داده ها در سرتاسر اینترنت است.
با استفاده از آموزش وب اسکرپینگ در PHP می توانید میلیون ها رکورد از اطلاعات مورد نیاز خود را از وب سایت های مختلف در کوتاه ترین زمان ممکن جمع آوری کنید.
وب اسکرپینگ (استخراج داده از صفحات وب) قبل از بوجود آمدن API ها استفاده می شد که الان اهمیت آن دوچندان شده است چراکه سایت های زیادی APIی برای دسترسی به یک سری داده ها را ارایه نمی دهند و ما ناچاریم که با وب اسکرپینگ (Web Scraping) تمام اطلاعات صفحه را بصورت HTML دریافت و با تجزیه (parse) کردن آن به داده مورد نظر برسیم.
در این آموزش قصد داریم به شما نحوه استخراج و دریافت اطلاعات فیلم از imdb با php را توسط روش وب اسکرپینگ را نشان بدیم.
سایت IMDB هیچ API عمومی ندارد, بنابراین ما نیاز داریم که این اطلاعات را از سایت scrape کنیم.
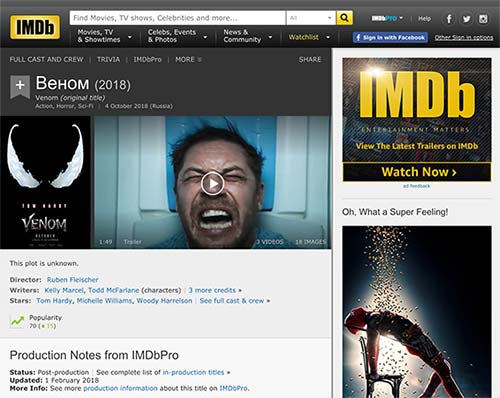
در این مثال ما اطلاعات زیر را از صفحه فیلم Venom در سایت imdb بدست می آوریم :
- عنوان
- توضیحات
- تاریخ انتشار
- ژانر
دلیل اینکه ما از کتابخانه ReactPHP استفاده می کنیم, سرعت بالای درخواست ها است. فرض کنید که ما تمام فیلم های صفحه Coming Soon را اسکرپ می کنیم. که دارای ۱۲ صفحه است و هر صفحه ۲۰ فیلم را داراست. بنابراین ۲۴۰ درخواست نیاز داریم که خب ارسال این درخواست ها پشت سر هم می توانید کمی زمانبر باشد…
حالا تصور کنید تمام این درخواست ها را بصورت همزمان (concurrently) ارسال کنیم. با این روش اسکرپر ما بطور قابل توجهی سریع خواهد بود.
نصب پیش نیازها
قبل از شروع کدنویسی اسکرپر نیاز است که پکیج های مورد نیاز را توسط کامپوزر به پروژه تزریق کنیم. (آموزش composer در PHP)
ما از کلاینت HTTP بنام buzz-react استفاده می کنیم.
|
1 |
composer require clue/buzz-react |
برای Dom نیز از DomCrawler سیمفونی بهره می بریم.
|
1 |
composer require symfony/dom-crawler |
Css-selector نیز به DomCrawler اجازه می دهد که سلکتور ها را مانند جی کویری استفاده کند.
|
1 |
composer require symfony/css-selector |
حالا می توانیم کدنویسی را شروع کنیم:
|
1 2 3 4 5 6 7 8 |
<?php use Clue\React\Buzz\Browser; $loop = React\EventLoop\Factory::create(); $client = new Browser($loop); // ... |
ما نمونه حلقه رویداد و کلاینت HTTP ایجاد کردیم. حالا میریم سراغ ارسال درخواست
ارسال درخواست به سایت IMDB
کلاینت Clue\React\Buzz\Browser دارای متد های زیادی مانند get(), post(), put() و غیره می باشد و ما اینجا برای ارسال درخواست get از متد get($url, $headers = [] ) استفاده می کنیم.
|
1 2 3 4 5 6 7 8 |
<?php // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { echo $response->getBody() . PHP_EOL; }); |
کد بالا کل خروجی صفحه درخواست شده را بازگشت می دهد. زمانی که پاسخ (response) دریافت شد می توانیم از نمونه Psr\Http\Message\ResponseInterface برای مدیریت پاسخ برگشتی و پروسس کردن آن استفاده کنیم.
تجزیه آبجکت DOM
صفحه فیلم IMDB نیاز به احراز هویت ندارد. همچنین اگر سورس صفحه را ببینید تمام اطلاعاتی که نیاز داریم از قبل در HTML وجود دارد. بنابراین این کار بسیار ساده است
بعد از دریافت پاسخ ما شروع به تجزیه DOM می کنیم. و اینجا از DomCrawler سیمفونی استفاده می کنیم. برای شروع استخراج اطلاعات نیازه به ساخت نمونه Crawler داریم که رشته HTML را نیز می پذیرد.
|
1 2 3 4 5 6 7 8 9 10 |
<?php use \Symfony\Component\DomCrawler\Crawler; // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { $crawler = new Crawler((string) $response->getBody()); }); |
داخل این هندلر, ما نمونه Crawler را ساخته و پاسخ را به آن پاس می دیم. حالا با استفاده از سلکتور مشابه جی کویری داده های مورد نیاز را از HTML دریافت می کنیم.
عنوان
این عنوان داخل تگ h1 قرار دارد:
|
1 2 3 4 5 6 7 8 9 10 |
<?php // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { $crawler = new Crawler((string) $response->getBody()); $title = trim($crawler->filter('h1')->text()); }); |
متد filter() برای پیدا کردن یک المنت داخل DOM استفاده می شود و بعد ما با متن داخل آن را با استفاده از سلکتور مشابه جی کویری استخراج می کنیم.
|
1 |
var title = $('h1').text(); |
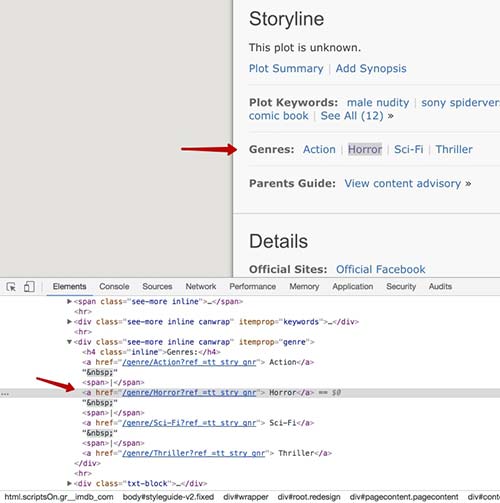
ژانر و توضیحات
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<?php // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { $crawler = new Crawler((string) $response->getBody()); $title = trim($crawler->filter('h1')->text()); $genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']); $description = trim($crawler->filter('[itemprop="description"]')->text()); }); |
تاریخ انتشار
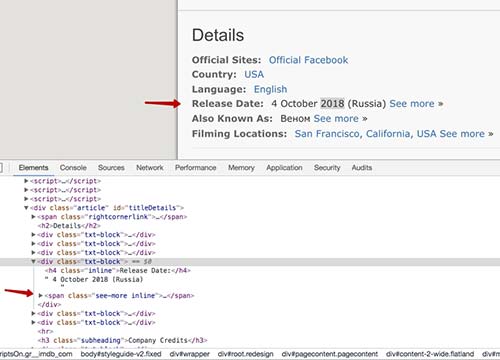
همانطور که دیدید داخل تگ <div> است اما بطور ساده نمی توان متن را از آن استخراج کرد. چرا که اگر اقدام کنیم چیزی مشابه این را دریافت می کنیم (Release Date: 16 February 2018 (USA) See more ») که مدنظر ما نیست
بنابراین قبل از استخراج متن تمام تگ های داخلی را حذف می کنیم :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<?php // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { $crawler = new Crawler((string) $response->getBody()); // ... $crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) { foreach ($crawler->children() as $node) { $node->parentNode->removeChild($node); } }); $releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text()); }); |
اینجا ما تمام تگ های <div> از بخش Details را انتخاب می کنیم. سپس, داخل حلقه, تمام تگ های فرزند را حذف می کنیم. این کد تمام تگ های <div> داخلی را انتخاب می کنیم برای همین ما برای دریافت تاریخ انتشار, چهارمین (ایندکس ۳) المنت را انتخاب و متن را از داخل آن می گیریم.
در مرحله آخر ما تمام داده ها را در یک آرایه جمع می کنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
<?php // ... $client->get('http://www.imdb.com/title/tt1270797/') ->then(function(\Psr\Http\Message\ResponseInterface $response) { $crawler = new Crawler((string) $response->getBody()); $title = trim($crawler->filter('h1')->text()); $genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']); $description = trim($crawler->filter('[itemprop="description"]')->text()); $crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) { foreach ($crawler->children() as $node) { $node->parentNode->removeChild($node); } }); $releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text()); return [ 'title' => $title, 'genres' => $genres, 'description' => $description, 'release_date' => $releaseDate, ]; }); |
استخراج و دریافت اطلاعات فیلم از imdb با php
حالا ما کل تکه کد ها را در کنار همدیگر داخل یک کلاس به نام Scraper جمع می کنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
<?php class Scraper { /** * @var Browser */ private $client; /** * @var array */ private $scraped = []; public function __construct(Browser $client) { $this->client = $client; } public function scrape(array $urls = []) { $this->scraped = []; foreach ($urls as $url) { $this->client->get($url)->then( function (\Psr\Http\Message\ResponseInterface $response) { $this->scraped[] = $this->extractFromHtml((string) $response->getBody()); }); } } public function extractFromHtml($html) { $crawler = new Crawler($html); $title = trim($crawler->filter('h1')->text()); $genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']); $description = trim($crawler->filter('[itemprop="description"]')->text()); $crawler->filter('#titleDetails .txt-block')->each( function (Crawler $crawler) { foreach ($crawler->children() as $node) { $node->parentNode->removeChild($node); } } ); $releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text()); return [ 'title' => $title, 'genres' => $genres, 'description' => $description, 'release_date' => $releaseDate, ]; } public function getMovieData() { return $this->scraped; } } |
متد سازنده این کلاس, نمونه Browser را دریافت می کند و ما دو متد برای دریافت اطلاعات فیلم و سریال داریم:
Scrape(array $urls)برای ارسال درخواست و تجزیه DOMgetMovieData()برای دریافت نتایج در زمانی که کار به اتمام رسیده است.
حالا در عمل قصد داریم اطلاعات دو فیلم مختلف را دریافت کنیم :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<?php // ... $loop = React\EventLoop\Factory::create(); $client = new Browser($loop); $scraper = new Scraper($client); $scraper->scrape([ 'http://www.imdb.com/title/tt1270797/', 'http://www.imdb.com/title/tt2527336/' ]); $loop->run(); print_r($scraper->getMovieData()); |
در کد بالا ما scraper را ایجاد و آدرس url دو فیلم را بصورت آرایه ای به آن پاس می دهیم.سپس در حلقه رویداد اجرا می شود تا زمانی که همه درخواست ها ارسال و اسکرپ به اتمام برسد.
بعد از آن نتیجه به این شکل برگشت داده می شود:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Array ( [0] => Array ( [title] => Venom (2018) [genres] => Array ( [0] => Action [1] => Horror [2] => Sci-Fi [3] => Thriller ) [description] => This plot is unknown. [release_date] => 4 October 2018 (Russia) ) [1] => Array ( [title] => Star Wars: Episode VIII - The Last Jedi (2017) [genres] => Array ( [0] => Action [1] => Adventure [2] => Fantasy [3] => Sci-Fi ) [description] => Rey develops her newly discovered abilities with the guidance of Luke Skywalker, who is unsettled by the strength of her powers. Meanwhile, the Resistance prepares for battle with the First Order. [release_date] => 14 December 2017 (Russia) ) ) |
شما می توانید این اطلاعات را در فایل یا دریتابیس ذخیره کنید. به هر حال هدف ما نمایش نحوه دریافت این اطلاعات و نشان دادن یک مثال کاربردی برای استخراج و دریافت اطلاعات فیلم از imdb با php بود.
یک راه آسان تر
بعضی وب سایت ها همین کاری که در این آموزش انجام دادیم را بصورت یک سرویس ارایه دادند که بعضی از آنها پولی و بعضی رایگان است که شما به راحتی می توانید از API آنها (غیر رسمی) استفاده کنید و اطلاعات فیلم و سریال را دریافت و نمایش یا ذخیره کنید.
کار بسیار عاقلانه در هنگام استفاده از این سرویس ها در یک پروژه واقعی و یا تجاری , ذخیره اطلاعات دریافتی در دیتابیس برای استفاده در سایت است چرا که اگر به هر دلیلی سرویس API مورد نظر فیلتر, محدود, پولی یا حتی از دسترس خارج شد به راحتی و بدون مشکل با جایگزین کردن آن بخش از کد, عملکرد آن بخش را احیا کنید.
|
1 |
http://www.omdbapi.com |
کافیست در سایت ثبت نام تا یک کد API دریافت کنید و بعد از کدهای نمونه آن یا cURL به آن درخواست ارسال و بعد خروجی json را واکشی و استفاده کنید
همچنین شما می توانید برای یک پروژه تجاری کدهایی که در این آموزش یاد گرفتید را به عنوان یک سرویس یا پکیج داخل خود پروژه قرار بدید تا هیچ نگرانی یا وابستگی به سرویس های خارجی نداشته باشید.
امیدوارم از آموزش استخراج و دریافت اطلاعات فیلم از imdb با php استفاده مفید را برده باشید.
برای دانلود سورس کد کامل از باکس دانلود زیر استفاده کنید.
هر سوالی داشتید ، از قسمت نظرات ارسال کنید . سریعا ، پاسخگوی سوالات شما هستیم .
موفق و پیروز باشید.





سلام وقت بخیر ، این آموزش و بخوام روی قالب وردپرس پیاده کنیم باید چیکار کنیم ؟ بازم باید پیش نیاز ها رو انجام بدیم ؟
سلام. ممنون.
بله باید انجام بشه
سلام ممنون از این مطلب خوبتون یه سوال اگر خواسته باشیم همین اطلاعات به صورت فارسی ذخیره بشه چکار باید بکنیم
سلام. سایت imdb خارجی هست و همه چیز انگلیسی نوشته میشه. اگر بخواید فارسی شه باید با api گوگل کار کنید اطلاعاتی که دریافت می کنید رو ترجمه و بعد ذخیره کنید
سلام
اسکریپتی که گذاشتید فایلهاش ناقص هست
مثلا سیمفونی کراور رو نداره یا کلا کمپوسر ناقص هست و پوشه وندر نداره درحالی که تغریبا توی همه فایلهاش پوشه وندر رو فراخوانی کرده و فایل
require __DIR__ . ‘/../../vendor/autoload.php’;
چک کنید
سلام. شما بعد دانلود داخل cmd وارد همان پوشه میشید و composer install رو میزنید
آموزش composer در php
آیا راهی برای براشتن محدودیت ۵۱۲ مگابایت حداقل رم مورد نیاز کمپوزر وجوود دارد…
بر روی vps با ۵۱۲mb رم خطای کمبود حافظه را میدهد
سلام. تا حالا این مورد رو تست نکردم به هر حال به اینصورت دستورات رو اجرا کنید ببینید نتیجه میده یا خیر.
export COMPOSER_MEMORY_LIMIT=-1 و بعد دستور composer را ران کنید و یا به اینصورت : php -d memory_limit=-1 composer.phar <...>
اگر نه که ابتدا پکیج را با کامپوزر روی سیستم شخصی کامل داده هاش رو دریافت کنید و بعد با ftp یا آپلود به روی vps خودتون انتقال بدید تا محدودیت دور زده بشه.